内核如何管理内存


在学习了进程的 虚拟地址布局 之后,让我们回到内核,来学习它管理用户内存的机制。这里再次使用 Gonzo:
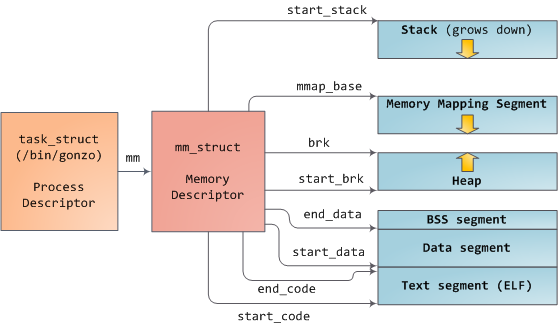
Linux 进程在内核中是作为进程描述符 task_struct (LCTT 译注:它是在 Linux 中描述进程完整信息的一种数据结构)的实例来实现的。在 task_struct 中的 mm 域指向到内存描述符,mm_struct 是一个程序在内存中的执行摘要。如上图所示,它保存了起始和结束内存段,进程使用的物理内存页面的 数量(RSS 常驻内存大小 Resident Set Size )、虚拟地址空间使用的 总数量、以及其它片断。 在内存描述符中,我们可以获悉它有两种管理内存的方式:虚拟内存区域集和页面表。Gonzo 的内存区域如下所示:
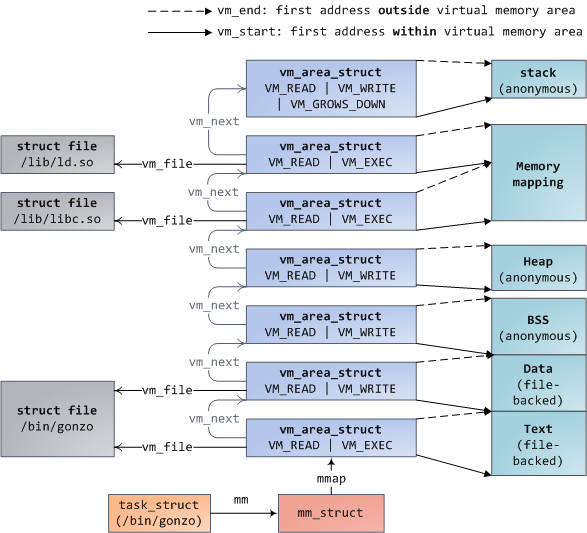
每个虚拟内存区域(VMA)是一个连续的虚拟地址范围;这些区域绝对不会重叠。一个 vm_area_struct 的实例完整地描述了一个内存区域,包括它的起始和结束地址,flags 决定了访问权限和行为,并且 vm_file 域指定了映射到这个区域的文件(如果有的话)。(除了内存映射段的例外情况之外,)一个 VMA 是不能匿名映射文件的。上面的每个内存段(比如,堆、栈)都对应一个单个的 VMA。虽然它通常都使用在 x86 的机器上,但它并不是必需的。VMA 也不关心它们在哪个段中。
一个程序的 VMA 在内存描述符中是作为 mmap 域的一个链接列表保存的,以起始虚拟地址为序进行排列,并且在 mm_rb 域中作为一个 红黑树 的根。红黑树允许内核通过给定的虚拟地址去快速搜索内存区域。在你读取文件 /proc/pid_of_process/maps 时,内核只是简单地读取每个进程的 VMA 的链接列表并显示它们。
在 Windows 中,EPROCESS 块大致类似于一个 task_struct 和 mm_struct 的结合。在 Windows 中模拟一个 VMA 的是虚拟地址描述符,或称为 VAD;它保存在一个 AVL 树 中。你知道关于 Windows 和 Linux 之间最有趣的事情是什么吗?其实它们只有一点小差别。
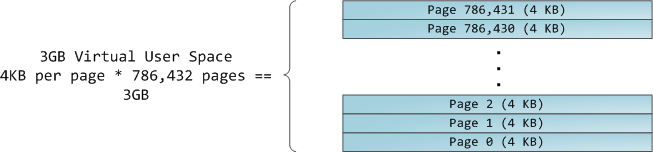
4GB 虚拟地址空间被分配到页面中。在 32 位模式中的 x86 处理器中支持 4KB、2MB、以及 4MB 大小的页面。Linux 和 Windows 都使用大小为 4KB 的页面去映射用户的一部分虚拟地址空间。字节 0-4095 在页面 0 中,字节 4096-8191 在页面 1 中,依次类推。VMA 的大小 必须是页面大小的倍数 。下图是使用 4KB 大小页面的总数量为 3GB 的用户空间:
处理器通过查看页面表去转换一个虚拟内存地址到一个真实的物理内存地址。每个进程都有它自己的一组页面表;每当发生进程切换时,用户空间的页面表也同时切换。Linux 在内存描述符的 pgd 域中保存了一个指向进程的页面表的指针。对于每个虚拟页面,页面表中都有一个相应的页面表条目(PTE),在常规的 x86 页面表中,它是一个简单的如下所示的大小为 4 字节的记录:

Linux 通过函数去 读取 和 设置 PTE 条目中的每个标志位。标志位 P 告诉处理器这个虚拟页面是否在物理内存中。如果该位被清除(设置为 0),访问这个页面将触发一个页面故障。请记住,当这个标志位为 0 时,内核可以在剩余的域上做任何想做的事。R/W 标志位是读/写标志;如果被清除,这个页面将变成只读的。U/S 标志位表示用户/超级用户;如果被清除,这个页面将仅被内核访问。这些标志都是用于实现我们在前面看到的只读内存和内核空间保护。
标志位 D 和 A 用于标识页面是否是“脏的”或者是已被访问过。一个脏页面表示已经被写入,而一个被访问过的页面则表示有一个写入或者读取发生过。这两个标志位都是粘滞位:处理器只能设置它们,而清除则是由内核来完成的。最终,PTE 保存了这个页面相应的起始物理地址,它们按 4KB 进行整齐排列。这个看起来不起眼的域是一些痛苦的根源,因为它限制了物理内存最大为 4 GB。其它的 PTE 域留到下次再讲,因为它是涉及了物理地址扩展的知识。
由于在一个虚拟页面上的所有字节都共享一个 U/S 和 R/W 标志位,所以内存保护的最小单元是一个虚拟页面。但是,同一个物理内存可能被映射到不同的虚拟页面,这样就有可能会出现相同的物理内存出现不同的保护标志位的情况。请注意,在 PTE 中是看不到运行权限的。这就是为什么经典的 x86 页面上允许代码在栈上被执行的原因,这样会很容易导致挖掘出栈缓冲溢出漏洞(可能会通过使用 return-to-libc 和其它技术来找出非可执行栈)。由于 PTE 缺少禁止运行标志位说明了一个更广泛的事实:在 VMA 中的权限标志位有可能或可能不完全转换为硬件保护。内核只能做它能做到的,但是,最终的架构限制了它能做的事情。
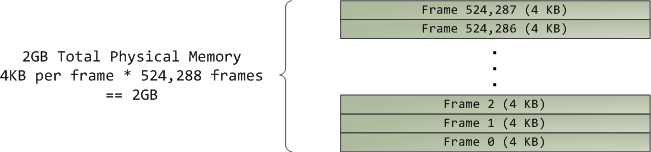
虚拟内存不保存任何东西,它只是简单地 映射 一个程序的地址空间到底层的物理内存上。物理内存被当作一个称之为物理地址空间的巨大块而由处理器访问。虽然内存的操作涉及到某些总线,我们在这里先忽略它,并假设物理地址范围从 0 到可用的最大值按字节递增。物理地址空间被内核进一步分解为页面帧。处理器并不会关心帧的具体情况,这一点对内核也是至关重要的,因为,页面帧是物理内存管理的最小单元。Linux 和 Windows 在 32 位模式下都使用 4KB 大小的页面帧;下图是一个有 2 GB 内存的机器的例子:
在 Linux 上每个页面帧是被一个 描述符 和 几个标志 来跟踪的。通过这些描述符和标志,实现了对机器上整个物理内存的跟踪;每个页面帧的具体状态是公开的。物理内存是通过使用 Buddy 内存分配 (LCTT 译注:一种内存分配算法)技术来管理的,因此,如果一个页面帧可以通过 Buddy 系统分配,那么它是未分配的(free)。一个被分配的页面帧可以是匿名的、持有程序数据的、或者它可能处于页面缓存中、持有数据保存在一个文件或者块设备中。还有其它的异形页面帧,但是这些异形页面帧现在已经不怎么使用了。Windows 有一个类似的页面帧号(Page Frame Number (PFN))数据库去跟踪物理内存。
我们把虚拟内存区域(VMA)、页面表条目(PTE),以及页面帧放在一起来理解它们是如何工作的。下面是一个用户堆的示例:
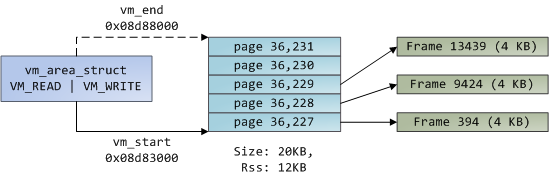
蓝色的矩形框表示在 VMA 范围内的页面,而箭头表示页面表条目映射页面到页面帧。一些缺少箭头的虚拟页面,表示它们对应的 PTE 的当前标志位被清除(置为 0)。这可能是因为这个页面从来没有被使用过,或者是它的内容已经被交换出去了。在这两种情况下,即便这些页面在 VMA 中,访问它们也将导致产生一个页面故障。对于这种 VMA 和页面表的不一致的情况,看上去似乎很奇怪,但是这种情况却经常发生。
一个 VMA 像一个在你的程序和内核之间的合约。你请求它做一些事情(分配内存、文件映射、等等),内核会回应“收到”,然后去创建或者更新相应的 VMA。 但是,它 并不立刻 去“兑现”对你的承诺,而是它会等待到发生一个页面故障时才去 真正 做这个工作。内核是个“懒惰的家伙”、“不诚实的人渣”;这就是虚拟内存的基本原理。它适用于大多数的情况,有一些类似情况和有一些意外的情况,但是,它是规则是,VMA 记录 约定的 内容,而 PTE 才反映这个“懒惰的内核” 真正做了什么。通过这两种数据结构共同来管理程序的内存;它们共同来完成解决页面故障、释放内存、从内存中交换出数据、等等。下图是内存分配的一个简单案例:
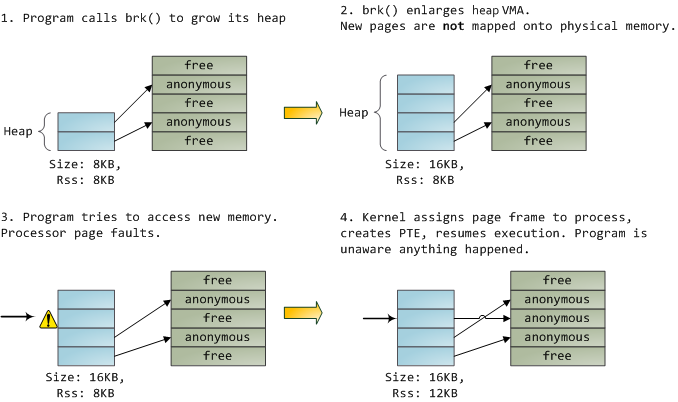
当程序通过 brk() 系统调用来请求一些内存时,内核只是简单地 更新 堆的 VMA 并给程序回复“已搞定”。而在这个时候并没有真正地分配页面帧,并且新的页面也没有映射到物理内存上。一旦程序尝试去访问这个页面时,处理器将发生页面故障,然后调用 do_page_fault()。这个函数将使用 find_vma() 去 搜索 发生页面故障的 VMA。如果找到了,然后在 VMA 上进行权限检查以防范恶意访问(读取或者写入)。如果没有合适的 VMA,也没有所尝试访问的内存的“合约”,将会给进程返回段故障。
当找到了一个合适的 VMA,内核必须通过查找 PTE 的内容和 VMA 的类型去处理故障。在我们的案例中,PTE 显示这个页面是 不存在的。事实上,我们的 PTE 是全部空白的(全部都是 0),在 Linux 中这表示虚拟内存还没有被映射。由于这是匿名 VMA,我们有一个完全的 RAM 事务,它必须被 do_anonymous_page() 来处理,它分配页面帧,并且用一个 PTE 去映射故障虚拟页面到一个新分配的帧。
有时候,事情可能会有所不同。例如,对于被交换出内存的页面的 PTE,在当前(Present)标志位上是 0,但它并不是空白的。而是在交换位置仍有页面内容,它必须从磁盘上读取并且通过 do_swap_page() 来加载到一个被称为 major fault 的页面帧上。
这是我们通过探查内核的用户内存管理得出的前半部分的结论。在下一篇文章中,我们通过将文件加载到内存中,来构建一个完整的内存框架图,以及对性能的影响。
via: http://duartes.org/gustavo/blog/post/how-the-kernel-manages-your-memory/
作者:Gustavo Duarte 译者:qhwdw 校对:wxy