ARPANET 协议是如何工作的
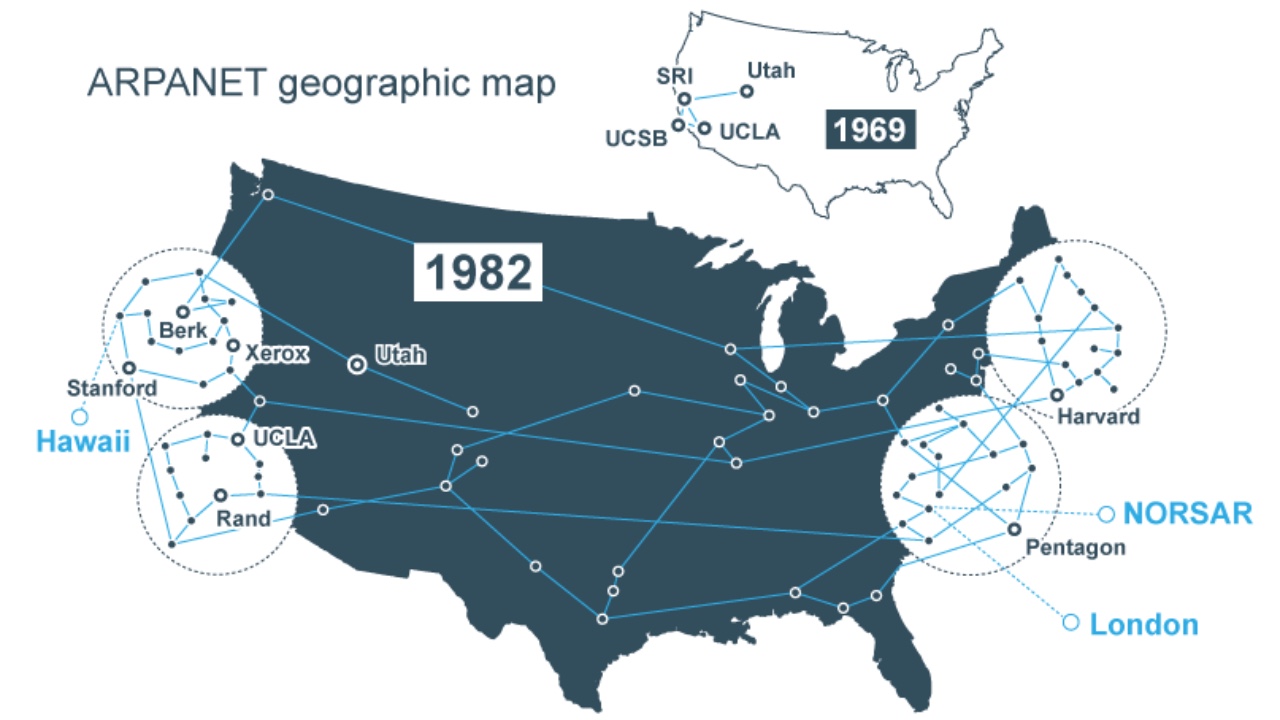
ARPANET 通过证明可以使用标准化协议连接完全不同的制造商的计算机,永远改变了计算。在我的 关于 ARPANET 的历史意义的文章 中,我提到了其中的一些协议,但没有详细描述它们。所以我想仔细看看它们。也想看看那些早期协议的设计有多少保留到了我们今天使用的协议中。
ARPANET 协议像我们现代的互联网协议,是通过分层形式来组织的。 [1] 较高层协议运行在较低层协议之上。如今的 TCP/IP 套件有 5 层(物理层、链路层、网络层、传输层以及应用层),但是这个 ARPANET 仅有 3 层,也可能是 4 层,这取决于你怎样计算它们。
我将会解释每一层是如何工作的,但首先,你需要知道是谁在 ARPANET 中构建了些什么,你需要知道这一点才能理解为什么这些层是这样划分的。
一些简短的历史背景
ARPANET 由美国联邦政府资助,确切的说是位于美国国防部的 高级研究计划局 Advanced Research Projects Agency (因此被命名为 “ARPANET” )。美国政府并没有直接建设这个网络;而是,把这项工作外包给了位于波士顿的一家名为 “Bolt, Beranek, and Newman” 的咨询公司,通常更多时候被称为 BBN。
而 BBN 则承担了实现这个网络的大部分任务,但不是全部。BBN 所做的是设计和维护一种称为 接口消息处理机 Interface Message Processor (简称为 IMP) 的机器。这个 IMP 是一种定制的 霍尼韦尔 Honeywell 小型机 minicomputer ,它们被分配给那些想要接入这个 ARPANET 的遍及全国各地的各个站点。它们充当通往 ARPANET 的网关,为每个站点提供多达四台主机的连接支持。它基本上是一台路由器。BBN 控制在 IMP 上运行的软件,把数据包从一个 IMP 转发到另一个 IMP ,但是该公司无法直接控制那些将要连接到 IMP 上并且成为 ARPANET 网络中实际主机的机器。
那些主机由网络中作为终端用户的计算机科学家们所控制。这些计算机科学家在全国各地的主机站负责编写软件,使主机之间能够相互通讯。而 IMP 赋予主机之间互相发送消息的能力,但是那并没有多大用处,除非主机之间能商定一种用于消息的格式。为了解决这个问题,一群杂七杂八的人员组成了网络工作组,其中有大部分是来自各个站点的研究生们,该组力求规定主机计算机使用的协议。
因此,如果你设想通过 ARPANET 进行一次成功的网络互动,(例如发送一封电子邮件),使这些互动成功的一些工程由一组人负责(BBN),然而其他的一些工程则由另一组人负责(网络工作组和在每个站点的工程师们)。这种组织和后勤方面的偶然性或许对推动采用分层的方法来管理 ARPANET 网络中的协议起到很大的作用,这反过来又影响了 TCP/IP 的分层方式。
好的,回到协议上来

ARPANET 协议层次结构
这些协议层被组织成一个层次结构,在最底部是 “Level 0”。 [2] 这在某种意义上是不算数的,因为在 ARPANET 中这层完全由 BBN 控制,所以不需要标准协议。Level 0 的作用是管理数据在 IMP 之间如何传输。在 BBN 内部,有管理 IMP 如何做到这一点的规则;在 BBN 之外,IMP 子网是一个黑匣子,它只会传送你提供的任意数据。因此,Level 0 是一个没有真正协议的层,就公开已知和商定的规则集而言,它的存在可以被运行在 ARPANET 的主机上的软件忽略。粗略地说,它处理相当于当今使用的 TCP/IP 套件的物理层、链路层和网络层下的所有内容,甚至还包括相当多的传输层,这是我将在这篇文章的末尾回来讨论的内容。
“Level 1” 层在 ARPANET 的主机和它们所连接的 IMP 之间建立了接口。如果你愿意,可以认为它是为 BBN 构建的 “Level 0” 层的黑匣子使用的一个应用程序接口(API)。当时它也被称为 IMP-Host 协议。必须编写该协议并公布出来,因为在首次建立 ARPANET 网络时,每个主机站点都必须编写自己的软件来与 IMP 连接。除非 BBN 给他们一些指导,否则他们不会知道如何做到这一点。
BBN 在一份名为 BBN Report 1822 的冗长文件中规定了 IMP-Host 协议。随着 ARPANET 的发展,该文件多次被修订;我将在这里大致描述 IMP-Host 协议最初设计时的工作方式。根据 BBN 的规则,主机可以将长度不超过 8095 位的消息传递给它们的 IMP,并且每条消息都有一个包含目标主机号和链路识别号的头部字段。 [3] IMP 将检查指定的主机号,然后尽职尽责地将消息转发到网络中。当从远端主机接收到消息时,接收的 IMP 在将消息传递给本地主机之前会把目标主机号替换为源主机号。实际上在 IMP 之间传递的内容并不是消息 —— IMP 将消息分解成更小的数据包以便通过网络传输 —— 但该细节对主机来说是不可见的。
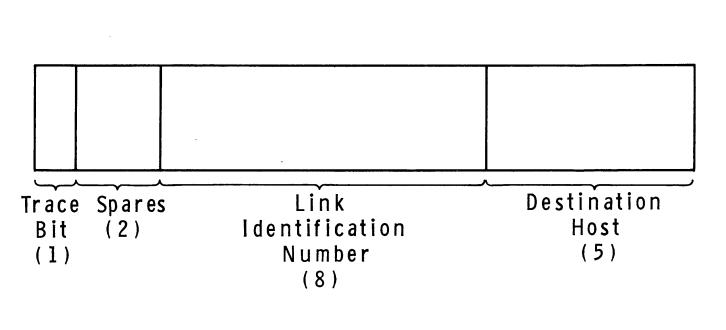
Host-IMP 消息头部格式,截至 1969。 图表来自 BBN Report 1763
链路号的取值范围为 0 到 255 ,它有两个作用。一是更高级别的协议可以利用它在网络上的任何两台主机之间建立多个通信信道,因为可以想象得到,在任何时刻都有可能存在多个本地用户与同一个目标主机进行通信的场景(换句话说,链路号允许在主机之间进行多路通信)。二是它也被用在 “Level 1” 层去控制主机之间发送的大量流量,以防止高性能计算机压制低性能计算机的情况出现。按照最初的设计,这个 IMP-Host 协议限制每台主机在某一时刻通过某条链路仅发送一条消息。一旦某台主机沿着某条链路发送了一条消息给远端主机后,在它沿着该链路发送下一条消息之前,必须等待接收一条来自远端的 IMP 的特别类型的消息,叫做 RFNM( 请求下一条消息 Request for Next Message )。后来为了提高性能,对该系统进行了修订,允许一台主机在给定的时刻传送多达 8 条消息给另一台主机。 [4]
“Level 2” 层才是事情真正开始变得有趣的地方,因为这一层和在它上面的那一层由 BBN 和国防部全部留给学者们和网络工作组自己去研发。“Level 2” 层包括了 Host-Host 协议,这个协议最初在 RFC9 中草拟,并且在 RFC54 中首次正式规定。在 ARPANET 协议手册 中有更易读的 Host-Host 协议的解释。
“Host-Host 协议” 管理主机之间如何创建和管理连接。“连接”是某个主机上的写套接字和另一个主机上的读套接字之间的一个单向的数据管道。“ 套接字 socket ” 的概念是在 “Level-1” 层的有限的链路设施(记住,链路号只能是那 256 个值中的一个)之上被引入的,是为了给程序提供寻址运行在远端主机上的特定进程的一种方式。“读套接字” 是用偶数表示的,而“写套接字”是用奇数表示的;套接字是 “读” 还是 “写” 被称为套接字的 “性别”。并没有类似于 TCP 协议那样的 “端口号” 机制,连接的打开、维持以及关闭操作是通过主机之间使用 “链路 0” 发送指定格式的 Host-Host 控制消息来实现的,这也是 “链路 0” 被保留的目的。一旦在 “链路 0” 上交换控制消息来建立起一个连接后,就可以使用接收端挑选的另一个链路号来发送进一步的数据消息。
Host-Host 控制消息一般通过 3 个字母的助记符来表示。当两个主机交换一条 STR( 发送端到接收端 sender-to-receiver )消息和一条配对的 RTS( 接收端到发送端 receiver-to-sender )消息后,就建立起了一条连接 —— 这些控制消息都被称为请求链接消息。链接能够被 CLS( 关闭 close )控制消息关闭。还有更多的控制信息能够改变从发送端到接收端发送消息的速率。从而再次需要确保较快的主机不会压制较慢的主机。在 “Level 1” 层上的协议提供了流量控制的功能,但对 “Level 2” 层来说显然是不够的;我怀疑这是因为从远端 IMP 接收到的 RFNM 只能保证远端 IMP 已经传送该消息到目标主机,而不能保证目标主机已经全部处理了该消息。还有 INR( 接收端中断 interrupt-by-receiver )、INS( 发送端中断 interrupt-by-sender )控制消息,主要供更高级别的协议使用。
更高级别的协议都位于 “Level 3”,这层是 ARPANET 的应用层。Telnet 协议,它提供到另一台主机的一个虚拟电传链接,其可能是这些协议中最重要的。但在这层中也有许多其他协议,例如用于传输文件的 FTP 协议和各种用于发送 Email 的协议实验。
在这一层中有一个不同于其他的协议: 初始链接协议 Initial Connection Protocol (ICP)。ICP 被认为是一个 “Level-3” 层协议,但实际上它是一种 “Level-2.5” 层协议,因为其他 “Level-3” 层协议都依赖它。之所以需要 ICP,是因为 “Level 2” 层的 Host-Host 协议提供的链接只是单向的,但大多数的应用需要一个双向(例如:全双工)的连接来做任何有趣的事情。要使得运行在某个主机上的客户端能够连接到另一个主机上的长期运行的服务进程,ICP 定义了两个步骤。第一步是建立一个从服务端到客户端的单向连接,通过使用服务端进程的众所周知的套接字号来实现。第二步服务端通过建立的这个连接发送一个新的套接字套接字号给客户端。到那时,那个存在的连接就会被丢弃,然后会打开另外两个新的连接,它们是基于传输的套接字号建立的“读”连接和基于传输的套接字号加 1 的“写”连接。这个小插曲是大多数事务的一个前提——比如它是建立 Telnet 链接的第一步。
以上是我们逐层攀登了 ARPANET 协议层次结构。你们可能一直期待我在某个时候提一下 “ 网络控制协议 Network Control Protocol ”(NCP) 。在我坐下来为这篇文章和上一篇文章做研究之前,我肯定认为 ARPANET 运行在一个叫 “NCP” 的协议之上。这个缩写有时用来指代整个 ARPANET 协议,这可能就是我为什么有这个想法的原因。举个例子,RFC801 讨论了将 ARPANET 从 “NCP” 过渡到 “TCP” 的方式,这使 NCP 听起来像是一个相当于 TCP 的 ARPANET 协议。但是对于 ARPANET 来说,从来都没有一个叫 “网络控制协议” 的东西(即使 大英百科全书是这样认为的),我怀疑人们错误地将 “NCP” 解释为 “ 网络控制协议 Network Control Protocol ” ,而实际上它代表的是 “ 网络控制程序 Network Control Program ” 。网络控制程序是一个运行在各个主机上的内核级别的程序,主要负责处理网络通信,等同于现如今操作系统中的 TCP/IP 协议栈。用在 RFC 801 的 “NCP” 是一种转喻,而不是协议。
与 TCP/IP 的比较
ARPANET 协议以后都会被 TCP/IP 协议替换(但 Telnet 和 FTP 协议除外,因为它们很容易就能在 TCP 上适配运行)。然而 ARPANET 协议都基于这么一个假设:就是网络是由一个单一实体(BBN)来构建和管理的。而 TCP/IP 协议套件是为网间网设计的,这是一个网络的网络,在那里一切都是不稳定的和不可靠的。这就导致了我们的现代协议套件和 ARPANET 协议有明显的不同,比如我们现在怎样区分网络层和传输层。在 ARPANET 中部分由 IMP 实现的类似传输层的功能现在完全由在网络边界的主机负责。
我发现 ARPANET 协议最有趣的事情是,现在在 TCP 中的许多传输层的功能是如何在 ARPANET 上经历了一个糟糕的青春期。我不是网络专家,因此我拿出大学时的网络课本(让我们跟着 Kurose 和 Ross 学习一下),他们对传输层通常负责什么给出了一个非常好的概述。总结一下他们的解释,一个传输层协议必须至少做到以下几点。这里的 “ 段 segment ” 基本等同于 ARPANET 上的术语 “ 消息 message ”:
- 提供进程之间的传送服务,而不仅仅是主机之间的(传输层多路复用和多路分解)
- 在每个段的基础上提供完整性检查(即确保传输过程中没有数据损坏)
像 TCP 那样,传输层也能够提供可靠的数据传输,这意味着:
- “段” 是按顺序被传送的
- 不会丢失任何 “段”
- “段” 的传送速度不会太快以至于被接收端丢弃(流量控制)
似乎在 ARPANET 上关于如何进行多路复用和多路分解以便进程可以通信存在一些混淆 —— BBN 在 IMP-Host 层引入了链路号来做到这一点,但结果证明在 Host-Host 层上无论如何套接字号都是必要的。然后链路号只是用于 IMP-Host 级别的流量控制,但 BBN 似乎后来放弃了它,转而支持在唯一的主机对之间进行流量控制,这意味着链路号一开始是一个超载的东西,后来基本上变成了虚设。TCP 现在使用端口号代替,分别对每一个 TCP 连接单独进行流量控制。进程间的多路复用和多路分解完全在 TCP 内部进行,不会像 ARPANET 一样泄露到较低层去。
同样有趣的是,鉴于 Kurose 和 Ross 如何开发 TCP 背后的想法,ARPANET 一开始就采用了 Kurose 和 Ross 所说的一个严谨的 “ 停止并等待 stop-and-wait ” 方法,来实现 IMP-Host 层上的可靠的数据传输。这个 “停止并等待” 方法发送一个 “段” 然后就拒绝再去发送更多 “段” ,直到收到一个最近发送的 “段” 的确认为止。这是一种简单的方法,但这意味着只有一个 “段” 在整个网络中运行,从而导致协议非常缓慢 —— 这就是为什么 Kurose 和 Ross 将 “停止并等待” 仅仅作为在通往功能齐全的传输层协议的路上的垫脚石的原因。曾有一段时间 “停止并等待” 是 ARPANET 上的工作方式,因为在 IMP–Host 层,必须接收到 请求下一条消息 Request for Next Message (RFNM)以响应每条发出的消息,然后才能发送任何进一步的消息。客观的说 ,BBN 起初认为这对于提供主机之间的流量控制是必要的,因此减速是故意的。正如我已经提到的,为了更好的性能,RFNM 的要求后来放宽松了,而且 IMP 也开始向消息中添加序列号和保持对传输中的消息的 “窗口” 的跟踪,这或多或少与如今 TCP 的实现如出一辙。 [5]
因此,ARPANET 表明,如果你能让每个人都遵守一些基本规则,异构计算系统之间的通信是可能的。正如我先前所说的,这是 ARPANET 的最重要的遗产。但是,我希望对这些基线规则的仔细研究揭示了 ARPANET 协议对我们今天使用的协议有多大影响。在主机和 IMP 之间分担传输层职责的方式上肯定有很多笨拙之处,有时候是冗余的。现在回想起来真的很可笑,主机之间一开始只能通过给出的任意链路在某刻只发送一条消息。但是 ARPANET 实验是一个独特的机会,可以通过实际构建和操作网络来学习这些经验,当到了是时候升级到我们今天所知的互联网时,似乎这些经验变得很有用。
如果你喜欢这篇贴子,更喜欢每四周发布一次的方式!那么在 Twitter 上关注 @TwoBitHistory 或者订阅 RSS 提要,以确保你知道新帖子的发布时间。
- 协议分层是网络工作组发明的。这个论点是在 RFC 871 中提出的。分层也是 BBN 如何在主机和 IMP 之间划分职责的自然延伸,因此 BBN 也值得称赞。 ↩︎
- “level” 是被网络工作组使用的术语。 详见 RFC 100 ↩︎
- 在 IMP-Host 协议的后续版本中,扩展了头部字段,并且将链路号升级为消息 ID。但是 Host-Host 协议仅仅继续使用消息 ID 字段的高位 8 位,并将其视为链路号。请参阅 ARPANET 协议手册 的 “Host-Host” 协议部分。 ↩︎
- John M. McQuillan 和 David C. Walden。 “ARPA 网络设计决策”,第 284页,https://www.walden-family.com/public/whole-paper.pdf。 2021 年 3 月 8 日查看。 ↩︎
- 同上。 ↩︎
via: https://twobithistory.org/2021/03/08/arpanet-protocols.html
作者:Two-Bit History 选题:lujun9972 译者:Lin-vy 校对:wxy